Introduction
Options de
configuration
Ordonnancement initial
Délai
inter-contrôles
Entrelacement des
services
Nombre maximal de contrôle de
services simultanés
Restrictions temporelles
Ordonnancement normal
Ordonnancement en cas de
problème
Contrôles d’hôtes
Délais d’ordonnancement
Exemple d’ordonnancement
Options de définition de service
affectant l’ordonnancement
J’ai reçu de nombreuses questions concernant la façon dont les contrôles de service sont ordonnancés dans certaines situations, ainsi que la différence d’ordonnancement entre l’exécution réelle des contrôles et le traitement de leur résultat. Cette page détaille ces mécanismes particuliers.
Avant de commencer, il y a plusieurs options de configuration qui affectent la manière dont les contrôles de service sont ordonnancés, exécutés, et traités. Pour les débutants, je rappelle que chaque définition de service contient trois options qui déterminent quand et comment chaque contrôle de service est ordonnancé et exécuté. Ces trois options sont :
Il y a également quatre options de configuration dans le fichier de configuration principal qui affectent les contrôles de services. Ce sont :
Nous verrons plus en détails comment ces options affectent les contrôles de service au fur et à mesure de notre explication. Tout d’abord, voyons comment les services sont ordonnancés lorsque Nagios® démarre ou redémarre…
Quand Nagios® (re)démarre, il essaie d’ordonnancer le contrôle initial de tous les services de manière à minimiser la charge imposée à l’hôte local et aux hôtes distants. Ceci est fait en espaçant les contrôles initiaux, et en les entrelaçant. L’espacement des contrôles (aussi appelé le délai inter-contrôles) est utilisé pour minimiser/égaliser la charge sur l’hôte supportant Nagios® et l’entrelacement permet de minimiser/égaliser la charge imposée aux hôtes distants. Le délai inter-contrôles et l’entrelacement sont tous deux décrits plus loin.
Bien que les contrôles des services soient initialement ordonnancés pour répartir la charge sur les hôtes, les choses vont évoluer à terme vers le chaos et être un peu faites au hasard. Cela est dû au fait que les services ne sont pas tous contrôlés à la même fréquence, que certains services mettent plus longtemps que d’autres à être contrôlés, que des problèmes sur les hôtes et/ou les services peuvent modifier l’ordonnancement des contrôles, etc. Au moins, nous essayons de faire partir les choses du bon pied. Avec un peu de chance, l’ordonnancement initial permettra de garder la charge assez équilibrée au fil du temps…
Note : si vous voulez connaître l’ordonnancement initial, démarrez Nagios® avec l’option -s. Cela affichera des informations sommaires sur l’ordonnancement (délai inter-contrôles, facteur d’entrelacement, heure du premier et du dernier contrôle de service, etc) et créera un nouveau journal des états qui montre à quelle heure exactement sont ordonnancés les contrôles initiaux de chaque service. Comme cette option écrase le journal des états, vous ne devez pas l’utiliser lorsqu’une autre instance de Nagios® tourne. Nagios® ne démarre aucune supervision lorsque cette option est utilisée.
Comme indiqué précédemment, Nagios® tente d’équilibrer la charge imposée à la machine qui le supporte en espaçant régulièrement les contrôles de services. Le temps d’attente entre deux contrôles consécutifs est appelé délai inter-contrôles. En donnant une valeur à la variable méthode de délai inter-contrôles du fichier de configuration principal, vous pouvez modifier la façon dont ce délai est calculé. J’expliquerai comment le calcul "débrouillard" [smart] fonctionne, car c’est le paramètre que vous utiliserez normalement.
En utilisant la valeur "débrouillard" [smart] pour la variable service_inter_check_delay_method, Nagios® calculera le délai inter-contrôles de la manière suivante :
délai inter-contrôles = (total des intervalles de contrôle normaux de tous les services) / (nombre total de services)
Prenons un exemple. Supposons que vous ayez 1.000 services ayant chacun un intervalle normal de contrôle de 5 minutes (normalement les services ne sont pas tous contrôlés à la même fréquence, mais prenons le cas le plus simple…). Le total des intervalles de contrôle de tous les services est de 5.000 (1.000 * 5). Ce qui signifie que le délai moyen entre deux contrôles de chaque service est de 5 minutes (5.000 / 1.000). Partant de cette information, nous réalisons que (en moyenne) il nous faut contrôler 1.000 services toutes les 5 minutes. Cela signifie qu’il nous faut utiliser un délai inter-contrôles de 0.005 minutes (0.3 secondes) lors de la répartition initiale des contrôles de services. En espaçant chaque contrôle de 0.3 secondes, nous pouvons plus ou moins garantir que Nagios® ordonnance et/ou exécute 3 nouveaux contrôles de services chaque seconde. En espaçant régulièrement les contrôles dans le temps de cette manière, nous pouvons espérer que la charge sur l’hôte qui supporte Nagios® reste équilibrée.
Comme décrit ci-dessus, le délai inter-contrôles aide à répartir la charge que Nagios® impose à l’hôte local. Qu’en est-il des hôtes distants ? Est-il nécessaire d’y répartir également la charge ? Pourquoi ? Oui, c’est important et oui, Nagios® peut y contribuer. Répartir la charge sur les hôtes distants est particulièrement important avec la mise en place de la parallélisation des contrôles de services. Si vous supervisez un grand nombre de services sur un hôte distant et que les contrôles ne sont pas répartis, l’hôte distant peut se croire victime d’une attaque SYN s’il y a de nombreuses connexions ouvertes sur le même port. De plus, tenter de répartir la charge sur les hôtes distants est une bonne chose…
En donnant une valeur à la variable facteur d’entrelacement des services du fichier de configuration principal, vous pouvez modifier le mode de calcul de l’entrelacement. J’expliquerai comment le calcul "débrouillard" fonctionne, comme c’est probablement le mode que vous utiliserez en général. Vous pouvez toutefois utiliser un facteur d’entrelacement prédéfini plutôt que de laisser Nagios® le calculer pour vous. Notez par ailleurs que si vous utilisez un facteur d’entrelacement de 1, le contrôle entrelacé des services est désactivé.
Quand vous utilisez la valeur "débrouillard" pour la variable service_interleave_factor, Nagios® calculera un facteur d’entrelacement selon la méthode suivante :
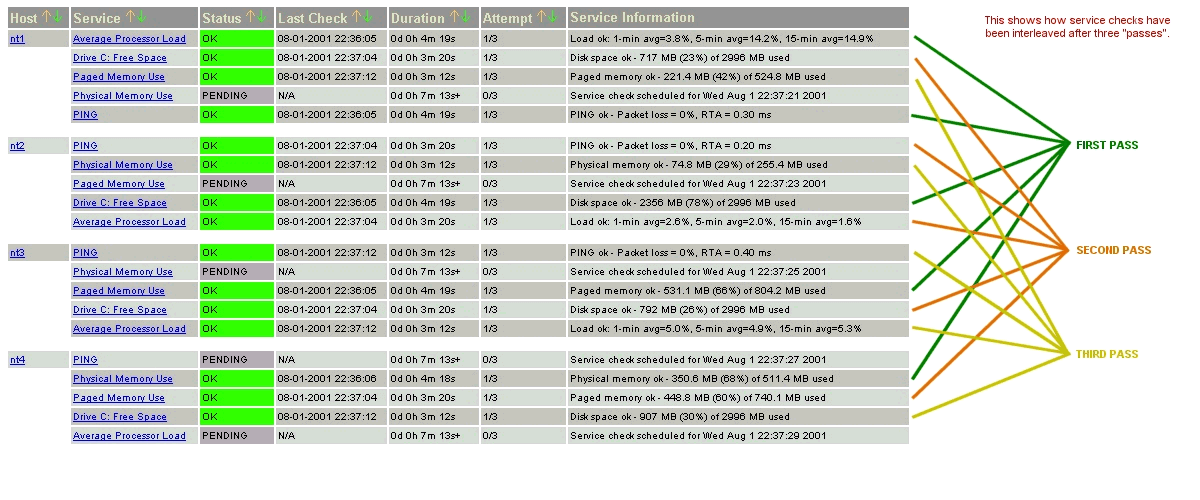
facteur d’entrelacement = plafond( nombre total de services / nombre total d’hôtes )
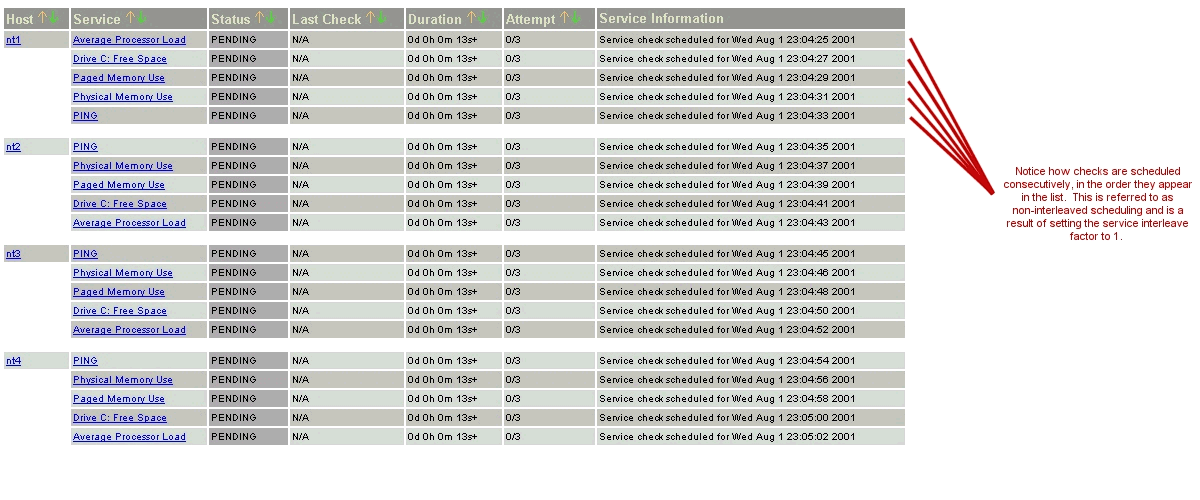
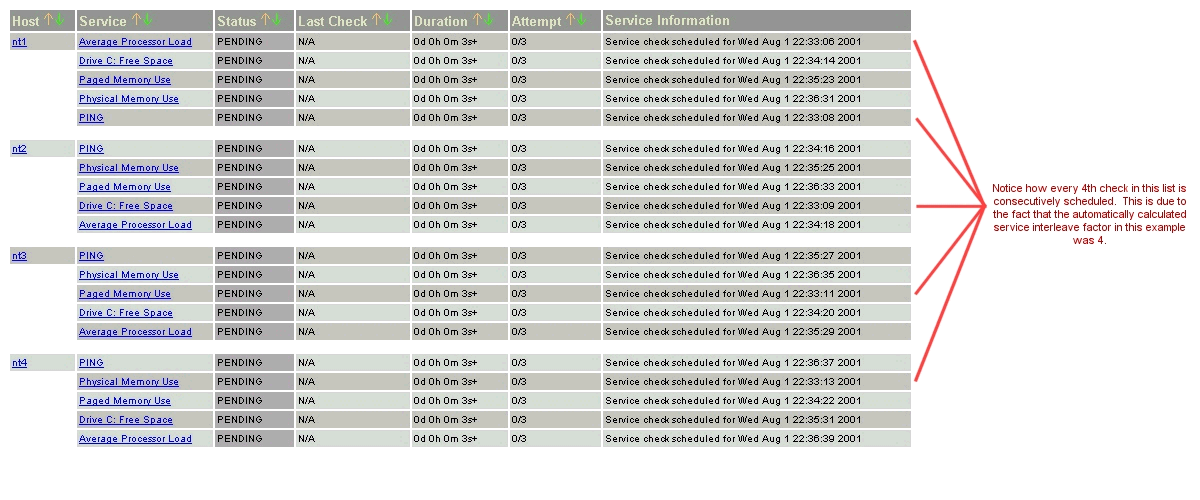
Prenons un exemple. Mettons que vous ayez un total de 1.000 services et 150 hôtes à superviser. Nagios® calculera un facteur d’entrelacement de 7. Ceci signifie que quand Nagios® ordonnance les contrôles initiaux des services, il ordonnancera le premier qu’il trouvera, sautera les 6 suivants, ordonnancera le suivant, et ainsi de suite… Ce processus se répétera jusqu’à ce que tous les contrôles de service soient ordonnancés. Comme les services sont triés (et donc ordonnancés) selon le nom de l’hôte auquel ils sont associés, cela aidera à minimiser/répartir la charge sur les hôtes distants.
Les deux images suivantes montrent comment les contrôles de services sont ordonnancés quand ils sont ne sont pas entrelacés (service_interleave_factor=1) et quand ils sont entrelacés avec la variable service_interleave_factor égal à 4.
| Non-Interleaved Checks: | Interleaved Checks: |
|---|---|
|
|
|
|
|
Pour éviter que Nagios® ne consomme toute votre CPU, vous pouvez restreindre le nombre maximal de contrôles de services qui peuvent s’exécuter à un instant donné. Ceci est défini grâce à l’option nombre maximal de contrôles de service simultanés (max_concurrent_checks) du fichier de configuration principal.
Le bon côté de cette option est que vous pouvez contrôler l’usage que fait Nagios® de votre CPU. Le mauvais côté est que des contrôles de services peuvent ne pas pouvoir s’exécuter si cette valeur est trop basse. Quand arrive le moment de faire un contrôle de service, Nagios® s’assurera que pas plus de x contrôles de services ne sont en cours d’exécution ou en attente de résultat (x étant la valeur que vous avez donné à l’option max_concurrent_checks). Si cette limite est atteinte, Nagios® retardera l’exécution des contrôles à faire jusqu’à ce que les précédents contrôles aient terminé. Dans ce cas, comment déterminer une valeur raisonnable pour l’option max_concurrent_checks ?
Tout d’abord, rassemblez les informations suivantes…
Ensuite, faites le calcul suivant pour déterminer une valeur raisonnable pour le nombre maximal de contrôles simultanés…
max. contrôles simultanés = plafond( max( fréquence de consolidation des services, temps moyen d’exécution d’un contrôle) / délai inter-contrôles)
Le résultat devrait donner une valeur de départ raisonnable pour la variable max_concurrent_checks. Vous pouvez avoir à augmenter un peu cette valeur si les contrôles de services continuent à dépasser l’heure ordonnancée ou à la réduire si Nagios® consomme trop de CPU.
Mettons que vous supervisez 875 services, chacun avec un intervalle de contrôle de 2 minutes. Cela signifie que votre délai inter-contrôles vaut 0,137 secondes. Si vous mettez la fréquence de consolidation des services à 10 secondes, vous pouvez calculer une valeur approximative pour le nombre maximal de contrôles simultanés comme suit (je suppose que le temps d’exécution moyen d’un contrôle est de moins de 10 secondes) …
max. contrôles simultanés = plafond( 10 / 0,137 )
Dans ce cas, le résultat est 73. Ceci est logique, car (en moyenne) Nagios® exécutera un peu plus de 7 nouveaux contrôles de service par seconde et il traite les résultats des contrôles toutes les 10 secondes. Ce qui veut dire qu’à n’importe quel moment, il y aura un peu plus de 70 contrôles de service en cours d’exécution ou en attente de traitement des résultats. Dans ce cas, je recommanderais de pousser la valeur du nombre maximal de contrôles simultanés jusqu’à 80, étant donné qu’il y aura de l’attente quand Nagios® traite les résultats des contrôles et fait le reste de son travail. Visiblement, vous devrez tester et régler les choses petit à petit pour que tout tourne correctement sur votre système, mais vous avez là des règles de configuration générales…
L’option check_period détermine la période durant laquelle Nagios® peut exécuter des contrôles de service. Sans parler de l’état dans lequel se trouve un service, si l’heure de son exécution réelle n’est pas une heure valide telle que spécifiée dans la période, le contrôle ne sera pas exécuté. Nagios® réordonnancera alors le contrôle à la prochaine heure valide de la période. Si le contrôle peut être exécuté (e.g. l’heure est validée dans la période), le contrôle est exécuté.
Note : même si un contrôle de service ne peut pas être exécuté à une certaine heure, Nagios® peut quand même l’ordonnancer à cette heure. Ce cas de figure se produira très probablement durant l’ordonnancement initial des contrôles de services, mais il peut aussi se produire dans d’autre cas. Cela ne signifie pas que Nagios® exécutera le contrôle ! Au moment d’exécuter un contrôle de service, Nagios® vérifiera que le contrôle peut se dérouler à cette heure. Si ce n’est pas le cas, Nagios® n’exécutera pas le contrôle, mais le réordonnancera plus tard. Que cela ne vous induise pas en erreur ! L’ordonnancement et l’exécution des contrôles sont deux choses clairement distinctes (bien qu’en relation).
Dans un monde parfait, vous n’aurez pas de problèmes de réseau. Mais si cela arrivait, vous n’auriez pas besoin d’un outil de supervision réseau. Quoi qu’il en soit, quand tout tourne et que les services sont dans l’état OK, nous appellerons cela "normal". Les contrôles de service sont normalement ordonnancés à la fréquence spécifiée par l’option check_interval. C’est tout. Simple, non ?
Qu’arrive-t-il en cas de problème sur un service ? Eh bien, entre autres l’ordonnancement des contrôles est modifié. Si vous avez configuré l’option max_attempts de la définition du service à plus de 1, Nagios® contrôlera le service à nouveau avant de remonter le problème. Pendant que le service est à nouveau contrôlé (jusqu’à max_attempts fois), il est considéré comme étant dans un état "soft" (comme décrit ici) et des contrôles du service sont réordonnancés à la fréquence déterminée par l’option retry_interval.
Si Nagios® contrôle le service max_attempts fois et qu’il le trouve toujours dans un état non-OK, Nagios® mettra le service en état "hard", enverra des notifications aux contacts (le cas échéant), et commencera le ré ordonnancement des futurs contrôles du service à la fréquence déterminée par l’option check_interval.
Comme toujours, il y a des exceptions à la règle. Quand un contrôle de service retourne un état non-OK, Nagios® contrôlera l’hôte auquel est associé le service pour déterminer s’il est en fonction ou pas (voyez la note ci-dessous pour savoir de quelle façon). Si l’hôte n’est pas en fonction (i.e. il est soit hors fonction soit inaccessible), Nagios® mettra immédiatement le service dans un état hard non-OK et remettra le compteur d’essais à 1. Comme le service est dans un état hard non-OK, le contrôle de service sera réordonnancé à la fréquence normale spécifiée par l’option check_interval, plutôt que celle de l’option retry_interval.
A la différence des contrôles de services, les contrôles d’hôtes ne sont pas ordonnancés de manière régulière. Ils sont lancés à la demande, quand Nagios® en ressent le besoin. C’est une question courante des utilisateurs, qui a donc besoin d’être clarifiée.
Un des cas où Nagios® contrôle l’état d’un hôte est quand un contrôle de service retourne un état non-OK. Nagios® contrôle l’hôte pour déterminer s’il est en fonction, hors fonction, ou inaccessible. Si le premier contrôle d’hôte retourne un état non-OK, Nagios® continuera à demander des contrôles de l’hôte jusqu’à ce que (a) le nombre maximal de contrôles d’hôte (spécifié par l’option max_attempts de la définition d’hôte) soit atteint, ou (b) un contrôle de l’hôte retourne l’état OK.
Notez également - quand Nagios® contrôle l’état d’un hôte, il suspend tout autre action (exécution de nouveaux contrôles de services, traitement des résultats des contrôles de services, etc). Ceci peut ralentir un peu les choses et retarder les contrôles de service pendant quelques temps, mais il est indispensable de déterminer l’état de l’hôte avant que Nagios® puisse agir sur le(s) service(s) posant problème.
Il est à noter que l’ordonnancement et l’exécution des contrôles de service sont faits "au mieux". Les contrôles de service individuels sont considérés comme étant des événements de basse priorité dans Nagios®, ils peuvent donc être retardés si des événements de haute priorité doivent être exécutés. Sont par exemple des événements de haute priorité les rotations de fichier journal, les commandes de contrôle externes, et les événements de consolidation de service. Qui plus est, les contrôles d’hôtes ralentissent l’exécution et le traitement des contrôles de services.
L’ordonnancement de contrôles de services, leur exécution, et
le traitement de leurs résultats peuvent être un peu ardus à
comprendre, alors prenons un petit exemple. Regardez le diagramme
ci-dessous - je m’y référerai en expliquant comment fonctionnent
ces choses.
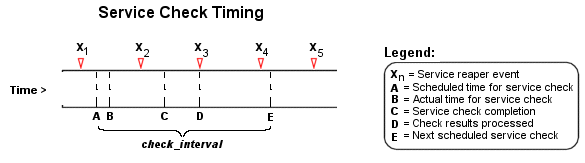
Tout d’abord, les événements Xn sont des événements de consolidation de services qui sont ordonnancés à une fréquence spécifiée par l’option fréquence de consolidation des services du fichier de configuration principal. Les événements de consolidation des services rassemblent et traitent les résultats des contrôles de service. Ils sont au cœur de Nagios®, lançant les contrôles d’hôte, les gestionnaires d’événements et les notifications si nécessaire.
Dans notre exemple, un service a été ordonnancé au moment A. Toutefois, Nagios® a pris du retard dans sa file d’événements, et donc le contrôle n’a été exécuté qu’au moment B. Le contrôle de service a terminé son exécution au moment C, donc la différence entre les points C et B est le temps pendant lequel le contrôle a effectivement tourné.
Les résultats du contrôle de service ne sont pas traités immédiatement à la fin de l’exécution. Ils sont sauvegardés pour un traitement ultérieur par l’événement de consolidation des services. Le prochain événement de ce type se produit au moment D, ce qui fait que c’est approximativement le moment auquel le résultat est traité (le moment réel peut se trouver un peu plus tard que D dans la mesure où d’autres résultats de contrôle de service peuvent être traités avant celui-ci).
Au moment où l’événement de consolidation des services traite le résultat du contrôle de service, il réordonnance le prochain contrôle de service et le place dans la file d’événements de Nagios®. Supposons que le contrôle de service retourne un état OK, le prochain moment de contrôle E se trouve à l’heure du contrôle original plus le temps spécifié par l’option check_interval. Notez que le service n’est pas réordonnancé selon le moment où il a été effectivement exécuté ! Il y a à ceci une exception (n’y en a t’il pas toujours ?) - si le moment ou le contrôle de service est réellement exécuté (point B) se trouve après le prochain moment d’exécution du contrôle (point E), Nagios® compensera en ajustant le prochain moment de contrôle. Ceci permet de s’assurer que Nagios® ne s’emballera pas à essayer de maintenir les contrôles de service en cas de charge importante. Qui plus est, quel intérêt d’ordonnancer quelque chose dans le passé…?
Chaque définition de service contient les options check_interval et retry_interval. J’espère ici clarifier le rôle de ces options, leur relation avec l’option max_attempts de la définition de service, et comment elles affectent l’ordonnancement du service.
Tout d’abord, l’option check_interval est l’intervalle de temps entre deux contrôles de service en temps "normal". "Normal" signifie lorsque le service est dans l’état OK ou quand il est dans un état hard non-OK.
Quand un service passe pour la première fois de l’état OK à l’état non-OK, Nagios® vous offre la possibilité d’augmenter ou de réduire temporairement l’intervalle de temps dont seront espacés les prochains contrôles de ce service. Quand un service change d’état pour la première fois, Nagios® fera jusqu’à max_attempts-1 tentatives de contrôle du service avant de décider que le problème est avéré. Pendant que le service est contrôlé à nouveau , il est ordonnancé selon l’option retry_interval, qui peut être plus courte ou plus longue que l’option check_interval. Pendant que le service est contrôlé (jusqu’à max_attempts-1 fois), il est dans un état soft. Si le service est contrôlé max_attempts-1 fois et qu’il est encore en état non-OK, le service passe en état hard et est ensuite ré ordonnancé à la fréquence normale spécifiée dans l’option check_interval.
A ce sujet, si vous spécifiez une valeur de 1 pour l’option max_attempts, le service ne sera jamais contrôlé à l’intervalle spécifié par l’option retry_interval. Il passera immédiatement dans un état hard et sera ensuite ré ordonnancé à la fréquence spécifiée par l’option check_interval.