Nagios® peut être configuré pour supporter la supervision répartie des services et ressources du réseau. Je vais essayer d'expliquer brièvement comment cela peut s'effectuer…
Le but de l'environnement de supervision réparti que je vais décrire est de décharger l'excès de charge induit par les contrôle de services (sur la CPU, etc.) du serveur central sur un ou plusieurs serveurs "répartis". La plupart des petites et moyennes entreprises n'auront pas réellement besoin de mettre en œuvre cet environnement. Cependant, quand vous voulez superviser des centaines, voire des milliers d'hôtes (et plusieurs fois cette valeur en termes de services) à l'aide de Nagios®, cela commence à devenir important.
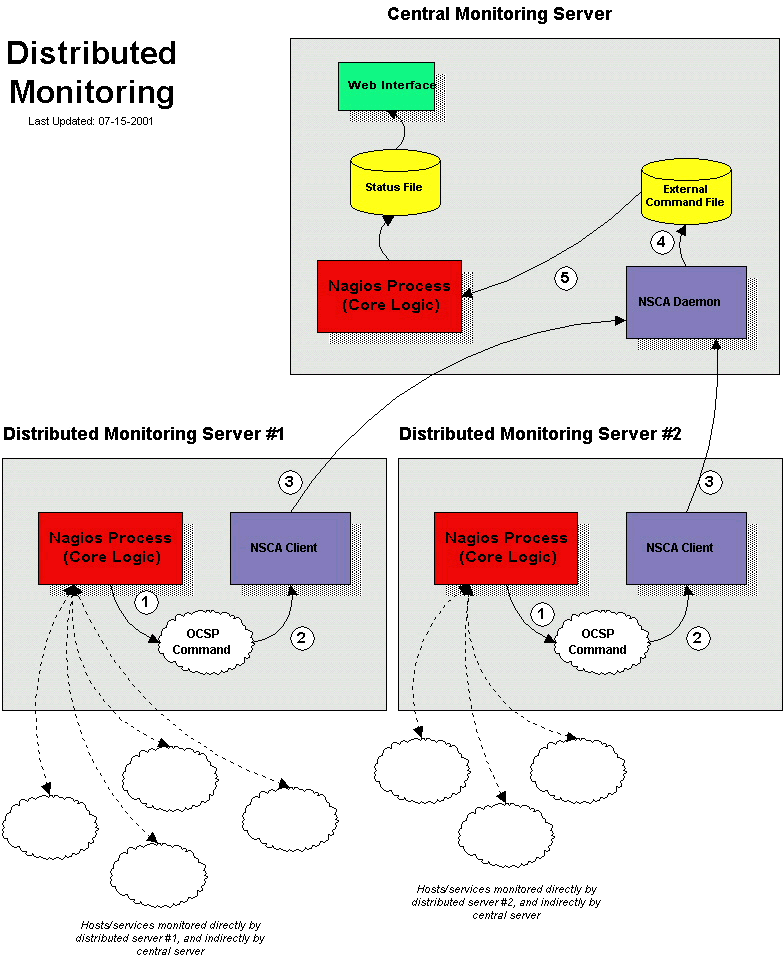
Le diagramme ci-dessous devrait vous aider à vous faire une
idée du fonctionnement de la supervision répartie avec Nagios®. Je
ferai référence aux éléments du diagramme quand j'expliquerai les
choses…
Quand on installe l'environnement de supervision réparti avec Nagios®, il y a des différences entre la configuration du serveur central et celle des serveurs répartis. Je vous montrerai comment configurer ces deux types de serveurs et j'expliquerai les effets des changements sur la supervision en général. A l'intention des débutants, décrivons d'abord l'utilité des différents serveurs…
Le rôle d'un serveur réparti est de contrôler tous les services définis pour une grappe [cluster] d'hôtes. J'utilise ce terme "grappe" de manière inappropriée : il désigne simplement un groupe d'hôtes de votre réseau. Selon la topographie de votre réseau, vous pouvez avoir plusieurs grappes en un seul lieu, ou chaque grappe peut être séparée par un WAN, un pare-feu, etc. Il faut surtout se souvenir d'une chose, c'est que pour chaque groupe d'hôtes (de quelque manière que vous le définissiez), il y a un serveur réparti sur lequel Nagios® tourne et qui supervise les services des hôtes du cluster. Un serveur réparti est généralement une installation simplifiée de Nagios®. Il n'est pas besoin d'installer l'interface web, d'envoyer des notifications, de faire tourner les scripts de gestionnaires d'événements ou de faire autre chose que l'exécution des contrôles de service si vous ne le souhaitez pas. De plus amples explications relatives à la configuration du serveur réparti suivront…
Le but du serveur central est d'écouter simplement les résultats des contrôles de service d'un ou de plusieurs serveurs répartis. Même si les services sont occasionnellement contrôlés activement par le serveur central, les contrôles actifs sont seulement exécutés dans des circonstances particulières ; disons donc pour l'instant que le serveur central n'accepte que les contrôles passifs. Comme le serveur central obtient des résultats des contrôles de services passifs d'un ou plusieurs serveurs répartis, il est utilisé comme point central pour la logique de supervision (i.e il envoie des notifications, exécute les scripts de gestionnaires d'événements, détermine l'état des hôtes, son interface web est installée, etc.).
Avant de sauter à pieds joints dans les détails de la configuration, il faut savoir comment envoyer les résultats des contrôles de service des serveurs répartis au serveur central. J'ai déjà expliqué comment soumettre des résultats de contrôles passifs à Nagios® à partir de la machine même sur laquelle Nagios® tourne (cf. documentation sur les contrôles passifs), mais je n'ai pas fourni d'information sur la manière d'envoyer des résultats de contrôles de service à partir d'autres hôtes.
Afin de faciliter l'envoi de résultats de contrôles passifs à un hôte distant, j'ai écrit le module complémentaire nsca. Il contient deux parties. La première est un programme client (send_nsca) qui tourne sur un hôte distant et envoi les résultats de contrôles de service à un autre serveur. La seconde est le démon nsca (nsca) qui fonctionne, soit comme un démon autonome, soit sous inetd, et écoute les connections des programmes du client. Après avoir reçu l'information de contrôle de service de la part d'un client, le démon enverra l'information de contrôle à Nagios® (sur le serveur central) en insérant une commande PROCESS_SVC_CHECK_RESULT dans le fichier de commande externe, avec les résultats du contrôle. La prochaine fois que Nagios® contrôlera les commandes externes, il trouvera l'information de contrôle de service passif qui avait été envoyée par le serveur réparti et la traitera. Elémentaire, non ?
Bon, comment Nagios® est-il configuré sur un serveur réparti ? A la base, c'est juste une simple installation. Il n'est pas nécessaire d'installer l'interface web ou de faire envoyer des notifications par le serveur, comme c'est le cas pour le serveur central.
Changements principaux dans la configuration :
Afin que tout fonctionne ensemble de manière correcte, nous voulons que le serveur réparti renvoie les résultats de tous les contrôles de service à Nagios®. Nous pourrions utiliser les gestionnaires d'événements pour envoyer les changements de l'état d'un service, mais cela ne fait pas l'affaire. Afin d'obliger le serveur réparti à envoyer tous les résultats des contrôles de service, il faut autoriser l'option de remontée de contrôle de service dans le fichier de configuration principal et permettre qu'une commande ocsp soit lancée après chaque contrôle de service. Nous utiliserons cette commande ocsp pour envoyer les résultats de tous les contrôles de service au serveur central, en utilisant le client send_nsca et le démon nsca (comme décrit ci-dessus) pour gérer la transmission.
Pour mener tout cela à bien, il faut définir la commande ocsp de cette façon :
ocsp_command=submit_check_result
La définition de la commande submit_check_result ressemble à ceci :
define command{
command_name submit_check_result
command_line /usr/local/nagios/libexec/eventhandlers/submit_check_result $HOSTNAME$ '$SERVICEDESC$' $SERVICESTATEID$ '$SERVICEOUTPUT$'
}
Le script shell submit_check_result ressemble à cela (remplacez central_server par l'adresse IP du serveur central) :
#!/bin/sh
# Arguments:
# $1 = host_name (Short name of host that the service is
# associated with)
# $2 = svc_description (Description of the service)
# $3 = state_string (A string representing the status of
# the given service - "OK", "WARNING", "CRITICAL"
# or "UNKNOWN")
# $4 = plugin_output (A text string that should be used
# as the plugin output for the service checks)
#
# Convert the state string to the corresponding return code
return_code=-1
case "$3" in
OK)
return_code=0
;;
WARNING)
return_code=1
;;
CRITICAL)
return_code=2
;;
UNKNOWN)
return_code=-1
;;
esac
# pipe the service check info into the send_nsca program, which
# in turn transmits the data to the nsca daemon on the central
# monitoring server
/bin/echo -e "$1\t$2\t$return_code\t$4\n" | /usr/local/nagios/bin/send_nsca central_server -c /usr/local/nagios/var/send_nsca.cfg
Le script ci-dessus suppose que vous avez le programme send_nsca et son fichier de configuration (send_nsca.cfg) placés respectivement dans les répertoires /usr/local/nagios/bin/ et /usr/local/nagios/var/.
C'est tout ! Nous venons de configurer avec succès un hôte distant sur lequel tourne Nagios® pour agir comme un serveur de supervision réparti. Voyons maintenant ce qui se passe exactement avec le serveur réparti et comment il envoie des résultats de contrôle de service à Nagios® (les étapes soulignées ci-dessous correspondent aux numéros du schéma de référence ci-dessus) :
Nous avons vu comment les serveurs de supervision répartis doivent être configurés, occupons nous maintenant du serveur central. Pour accomplir toutes ses missions, il est configuré de la même manière que vous configureriez un serveur seul. Il est installé de la manière suivante :
Il y a trois autres éléments importants que vous devez conserver à l'esprit en configurant le serveur central :
Il est important que vous désactiviez soit tous les contrôles de service pour l'ensemble du logiciel, soit l'option enable_active_checks dans la définition de tout service surveillé par un serveur réparti. Cela assure que les contrôles de service actifs ne sont jamais exécutés en temps normal. Les services continueront à être ordonnancés à leur intervalle de contrôle normal (3 minutes, 5 minutes, etc…), mais ils ne seront jamais exécutés. Cette boucle de ré ordonnancement continuera aussi longtemps que Nagios® tourne. Je vais expliquer bientôt pourquoi ce type de fonctionnement…
Et voilà ! Facile, non ?
Pour toutes les utilisations intensives, nous pouvons dire que le serveur central s'appuie uniquement sur les contrôles passifs pour la supervision. Faire totalement confiance aux contrôles passifs pour superviser pose un problème majeur : Nagios® doit se fier à quelque chose d'autre pour fournir les données supervisées. Que se passe-t-il si l'hôte distant qui envoie les résultats s'effondre ou devient injoignable ? Si Nagios® ne contrôle pas activement les services de cet hôte, comment saura-t-il qu'il y a un problème ?
Nous pouvons prévenir ce type de problèmes en utilisant un autre module complémentaire pour superviser les résultats des contrôles passifs qui arrivent…
Le contrôle de validité des données
Nagios® offre une fonctionnalité qui teste la validité des résultats d'un test. On peut trouver plus d'informations à ce sujet ici. Cette fonctionnalité apporte une solution aux situations ou les hôtes distants peuvent arrêter d'envoyer le résultat des tests passifs au serveur central. Elle permet d'assurer que le test est soit fourni passivement par les serveurs répartis, soit exécuté activement par le serveur central si nécessaire. Si les résultats fournis par le test du service deviennent "figés", Nagios® peut être configuré pour forcer un contrôle actif depuis le serveur central.
Comment fait-on cela ? Sur le serveur central, il faut configurer ainsi les services qui sont surveillés par les serveurs répartis:
Nagios® teste régulièrement la validité des résultats pour lesquels cette option est validée. L'option freshness_threshold dans chaque service détermine le niveau de validité pour celui-ci.
Par exemple, si sa valeur est 300 pour un de vos services, Nagios® va considérer que les résultats du service sont "figés" s'ils ont plus de 5 minutes (300 secondes). Si vous ne spécifiez pas la valeur de freshness_threshold, Nagios® calculera un seuil à partir de la valeur des options normal_check_interval ou de retry_check_interval (en fonction de l'état du service). Si les résultats sont "figés", Nagos exécutera la commande spécifiée dans check_command dans la définition du service, vérifiant ainsi activement ce service.
N'oubliez pas que vous devez définir l'option check_command dans la définition des services, pour pouvoir tester activement l'état d'un service depuis le serveur central. Dans des conditions normales, cette commande check_command ne sera pas exécutée (parce que les test actifs auront été désactivés globalement au niveau du programme, ou pour des services spécifiques). A partir du moment ou le contrôle de validité des données est activé, Nagios® exécutera cette commande, même si les tests actifs ont été désactivés globalement au niveau du programme ou pour des services spécifiques.
Si nous n'arrivez pas à définir des commandes pour tester activement un service depuis le serveur central (ou bien cela est un casse-tête douloureux), vous pouvez simplement définir toutes les options check_command d'après un simple script qui retourne un état "critique". Voici un exemple : supposons que vous ayez défini une commande "service_fige" et utilisez cette commande dans l'option check_command de vos services. Elle pourrait ressembler à cela …..
define command{
command_name service-fige
command_line /usr/local/nagios/libexec/service-fige.sh
}
Le programme "service_figé.sh " dans /usr/local/nagios/libexec pourrait ressembler à cela:
#!/bin/sh /bin/echo "CRITICAL: Les resultats du service sont figes!" exit 2
Ensuite, quand Nagios® détecte que les résultats sont figés et lance la commande service_fige.sh, le script /usr/local/nagios/libexec/service-fige.sh est exécuté et le service passe dans un état critique. Ceci déclenchera l'envoi de notifications, donc vous saurez finalement qu'il y a un problème.
Maintenant, vous savez comment obtenir des résultats de contrôles passifs depuis des serveurs répartis. Ceci signifie que le serveur central ne teste activement que ses propres services. Mais qu'en est-il des hôtes ? Vous en avez toujours besoin, non ?
Comme les tests des hôtes n'ont qu'un impact faible sur la surveillance (ils ne sont faits que s'ils sont vraiment nécessaires), je vous recommanderai bien de faire ces tests, de manière active, depuis le serveur central. Ceci signifie que vous définirez le test des hôtes sur le serveur central de la même manière que vous l'avez fait sur les serveurs répartis (également de la même manière que sur un serveur normal, non répartis).
Les résultats de contrôle passifs des hôtes sont disponible (ici), donc vous pourriez les utiliser dans votre architecture répartie mais cette méthode comporte certains problèmes. Le principal étant que Nagios® ne traduit pas les états problèmes (arrêtés [down] ou injoignables [unreachable]) retournés par les vérifications passives des hôtes quand ils sont traités. Par conséquent, si vos serveurs de supervision ont une structure différentes en terme de parents ou enfants (et c'est ce qui se passe lorsque vos serveurs de supervisions ne sont pas exactement au même endroit), le serveur central va avoir une vision incorrecte des états des hôtes.
Si vous voulez vraiment envoyer des résultats passifs de contrôle d'hôte à un serveur de supervision central, vérifiez que :
La commande ochp utilisé pour le traitement des vérifications d'hôte, fonctionne de manière similaire à la commande ocsp, utilisée pour le traitement des vérification des services (cf documentation ci dessus). Pour être sur que les vérifications passives d'hôte sont valides et à jour, il est nécessaire d'activer la validité des vérification pour les hôtes de la même manière que pour les services.