Nagios® supporte la détection optionnelle des hôtes et des services qui "oscillent" [NdT: ou bagotent]. L'oscillation intervient quand un service ou un hôte change d'état trop fréquemment, provoquant une tempête de notifications de problèmes et de rétablissement. L'oscillation peut être l'indice de problèmes de configuration (i.e. des seuils positionnés trop bas) ou de vrais problèmes sur le réseau.
Avant d'aller plus loin, permettez-moi de signaler qu'implémenter la détection de l'oscillation a été assez difficile. Comment déterminer ce que "trop fréquemment" veut dire concernant les changements d'état de tel hôte ou service ? La première fois que je me suis penché sur la détection de l'oscillation, j'ai cherché des informations sur la façon dont on peut ou doit procéder. Voyant que je n'en trouvais pas, j'ai décidé de définir ce qui pourrait être une solution raisonnable. Les méthodes utilisées par Nagios® pour détecter l'oscillation de l'état des hôtes et des services sont décrites ci-dessous…
Chaque fois d'un contrôle de service résulte dans un état hard ou un état de rétablissement soft, Nagios® contrôle si le service a commencé ou arrêté d'osciller. Il le fait en stockant les 21 derniers résultats de contrôle de service dans un tableau. Les résultats les plus récents écrasent les anciens dans le tableau.
Le contenu du tableau d'historique des états est parcouru (depuis le plus ancien résultat jusqu'au plus récent) pour déterminer le pourcentage total de changements d'état survenus durant les 21 derniers contrôles du service. Un changement d'état survient quand un état archivé est différent de l'état archivé qui le précède immédiatement dans le tableau. Comme nous conservons les résultats des 21 derniers contrôles de service dans le tableau, il y a 20 changements d'état possibles.
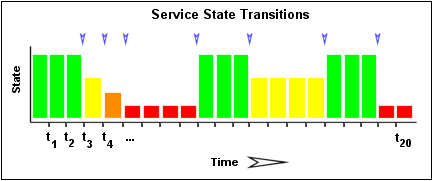
L'image 1 ci-dessous montre un tableau chronologique d'états de service. Les états OK sont en vert, les WARNING en jaune, les CRITICAL en rouge, et les UNKNOWN en orange. Des flèches bleues marquent les moments où des changements d'états sont survenus.
Image 1.
Les services qui changent rarement d'état auront un pourcentage moins élevé de changement d'état que ceux qui changent beaucoup d'état. Comme l'oscillation est associée avec des changements d'état fréquents, nous pouvons utiliser la valeur de changement d'état calculée pour une période donnée (dans notre cas, les 21 derniers contrôles de service) pour déterminer si un service oscille ou non. Mais ce n'est pas encore assez précis… /p>
Il paraît évident que les changements d'état les plus récent ont plus de poids que les anciens, si bien qu'il nous faut recalculer le pourcentage total de changements d'état du service selon une espèce de courbe… Pour simplifier, j'ai décidé d'utiliser un rapport linéaire entre le temps et la pondération pour le calcul de ce pourcentage. Les fonctions de détection de l'oscillation sont conçues actuellement pour que le changement d'état le plus récent possible pèse 50% plus lourd que le plus ancien. L'image 2 montre combien le poids des changements d'état récents est supérieur à celui des anciens lors du calcul du pourcentage total de changements d'état d'un service particulier. Si vous voulez savoir exactement comment ce calcul pondéré est réalisé, regardez le code dans base/flapping.c…
Image 2.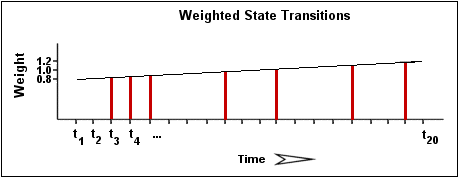
Prenons un rapide exemple de détection de l'oscillation. L'image 1 montre le tableau d'historique des résultats de contrôle d'un service particulier. Les résultats les plus anciens sont à gauche et les plus récents à droite. Nous voyons dans cet exemple qu'il y a eu au total 7 changements d'état (en t3, t4, t5, t9, t12, t16, et t19). Sans pondération des changements d'état en fonction du temps, cela nous donnerait un total de 35% de changements d'état (7 changements d'état sur un maximum possible de 20). Quand on applique la pondération en fonction du moment d'apparition, le pourcentage est de moins de 35%. C'est logique dans la mesure où la plupart des changements d'états sont plutôt anciens. Disons que le pourcentage pondéré est finalement de 31%…
Ainsi donc, que signifient 31% de changements d'états ? Hé bien, si le service n'oscillait pas auparavant et que 31% est supérieur ou égal à la valeur spécifiée par le paramètre high_service_flap_threshold de la définition du service, Nagios® considère que le service vient de commencer à osciller. Si le service oscillait auparavant et que 31% est inférieur ou égal à la valeur spécifiée par le paramètre low_service_flap_threshold de la définition du service, Nagios® considère que le service vient de s'arrêter d'osciller. Si aucune de ces deux conditions n'est remplie, Nagios® ne fait rien de plus concernant le service, car soit il n'oscille pas, soit il oscille toujours…
La détection de l'oscillation d'hôte fonctionne de manière similaire à la détection d'oscillation de service, avec une différence importante : Nagios® essaiera de déterminer si un hôte oscille à chaque contrôle de l'état de l'hôte et à chaque contrôle d'un service associé à cet hôte. Pourquoi cela ? Hé bien, parce qu'avec les services, nous savons que l'intervalle minimal de temps entre deux détections d'oscillation consécutives sera égal à l'intervalle de contrôle du service. Avec les hôtes, nous n'avons pas d'intervalle de contrôle, du fait que les hôtes ne sont pas supervisés de manière régulière. Ils ne sont contrôlés que lorsque c'est nécessaire. L'oscillation d'un hôte sera contrôlée si son état a changé depuis la dernière détection d'oscillation de cet hôte ou si son état n'a pas changé, mais qu'au moins x temps s'est écoulé depuis la dernière détection d'oscillation. Ce temps xest égal à la moyenne des intervalles de contrôles de tous les services associés avec l'hôte. C'est la meilleure méthode que j'ai pu imaginer pour déterminer la fréquence de la détection d'oscillation d'un hôte…
Comme pour les services, Nagios® stocke les résultats des 21 derniers contrôles d'oscillation d'hôte dans un tableau destiné à l'algorithme de détection d'oscillation. Les changements d'état sont pondérés en fonction du moment, et le pourcentage total de changements d'état est calculé de la même manière que dans l'algorithme de détection d'oscillation des services.
Si un hôte n'oscillait pas précédemment et que le calcul de son pourcentage total de changement d'état est supérieur ou égal à la valeur spécifiée dans le paramètre high_host_flap_threshold, Nagios® considère que l'hôte commence juste à osciller. Si l'hôte oscillait précédemment et que le calcul de son pourcentage total de changement d'état est inférieur ou égal à la valeur spécifiée par le paramètre low_host_flap_threshold, Nagios® considère que l'hôte vient d'arréter d'osciller. Si aucune de ces deux conditions n'est remplie, Nagios® ne fait rien de plus concernant l'hôte, car soit il n'oscille pas, soit il oscille toujours…
Si vous utilisez le fichier de définition des hôtes à base de modèles, vous pouvez spécifier un seuil de détection d'oscillation pour les hôtes et les services en ajoutant les directives low_flap_threshold et high_flap_threshold dans les définitions individuelles d'hôtes et services. Si ces directives ne sont pas présentes dans la définition d'un hôte ou d'un service, les valeurs globales de seuil seront utilisées.
De la même manière, vous pouvez activer/désactiver la détection d'oscillation pour des hôtes ou services particuliers avec la directive enable_flap_detection appliquée à la définition d'un objet. Notez que la détection d'oscillation doit être activée pour l'ensemble du programme Nagios® (avec la directive enable_flap_detection du fichier de configuration principal) si vous souhaitez que celle-ci fonctionne.
Quand un service ou un hôte commence à osciller, Nagios® fait trois choses :
Quand un service ou un hôte s'arrête d'osciller, Nagios® fait les chose suivantes :