Chapitre 42. Gestion de panne et redondance pour la supervision réseau
Table des matières
Introduction
Cette section décrit quelques scénarii d’implémentation de systèmes de supervision redondante ainsi que plusieurs topologies réseau. Avec la redondance des systèmes, vous pouvez maintenir la possibilité de surveiller votre réseau alors que le premier système sur lequel tourne Nagios pose problème ou lorsque des parties du réseau deviennent injoignables.
Si vous apprenez à utiliser Nagios, je suggère de ne pas essayer d’implémenter la redondance tant que vous n’êtes pas habitué aux pré-requis déjà présentés. La redondance est un sujet relativement complexe, et il est encore plus difficile de l’implémenter correctement.
Pré-requis
Avant de penser pouvoir implémenter la redondance avec Nagios, vous devez être familier avec ce qui suit…
-
Implémenter les Gestionnaires d’événements pour les hôtes et services
-
Présenter une commande externe à Nagios via des scripts shell
-
Exécuter des plugins sur des hôtes distants en utilisant soit NRPE, soit d’autres méthodes
-
Vérifier l’état du processus Nagios avec le plugin check_nagios
Exemples de scripts
Tous les exemples que j’utilise dans cette documentation se trouvent dans le répertoire eventhandlers/ de la distribution Nagios. Vous devrez probablement les modifier pour les faire fonctionner sur votre système…
Introduction
Ceci est une méthode facile (et naïve) pour implémenter le monitoring redondant d’hôtes sur votre réseau, qui protègera seulement contre un nombre limité de problèmes. Des réglages plus complexes sont nécessaires pour fournir une redondance plus pratique, une meilleure redondance à travers des segments réseau, etc.
Buts
Le but de ce type d’implémentation de redondance est simple. Les hôtes maître et esclave surveillent les mêmes systèmes et services sur le réseau. Dans des circonstances normales, le système maître prendra en charge l’envoi des notifications aux contacts concernant les problèmes détectés. Nous voulons que système esclave fasse fonctionner Nagios et prenne en charge la notification des problèmes si:
-
Soit le système Maître faisant fonctionner Nagios ne répond plus
-
Soit le processus Nagios sur le système Maître arrête de fonctionner.
Diagramme de topologie réseau
Le diagramme ci-dessous montre une configuration réseau très simple. Pour ce scénario, je vais supposer que les systèmes A et E font tourner tous deux Nagios et surveillent tous les systèmes que l’on y voit. Le système A sera considéré comme étant le système maître et le système E sera considéré comme étant l’esclave.
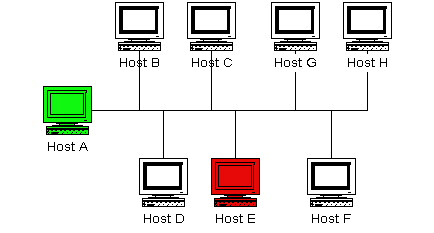
|
Réglages initiaux du programme
Le système esclave (système E) a son paramètre initial de notification enable_notifications désactivé, afin de lui éviter d’envoyer des notifications autant pour les hôtes que pour les services. Il faut aussi s’assurer que le système esclave a son paramètre check_external_commands activée. C’est plutôt simple…
Configuration Initiale
Il faudra ensuite considérer les changements entre le(s) fichier(s) de configuration des objets sur les systèmes maître et esclave…
Je vais supposer que le système maître (système A) est configuré pour surveiller des services sur tous les systèmes montrés dans le diagramme ci-dessus. Le système esclave (système E) doit être configuré pour surveiller les mêmes systèmes et services, avec les ajouts suivants aux fichiers de configuration…
-
La définition du système A (dans le fichier de configuration du système E) devrait avoir un gestionnaire d’événement défini. Supposons que le nom du gestionnaire d’événement pour le système s’appelle
handle-master-host-event. -
Le fichier de configuration sur le système E devrait avoir un service défini pour surveiller l’état du processus Nagios sur le système A. Supposons que vous ayez défini cette vérification de service pour lancer le plugin check_nagios sur le système A.
-
La définition du service pour la surveillance du processus Nagios sur le système A devrait être un gestionnaire d’événement. Supposons que ce service gestionnaire d’événement soit
handle-master-proc-event.
Il est important de noter que le système A (le système maître) ne sait rien du système E (le système esclave). Dans ce scénario, il n’en a simplement pas besoin. Bien évidemment, vous pouvez surveiller les services du système E depuis le système A, mais cela n’a rien à voir avec l’implémentation de la redondance…
Définition de commandes de Gestion d’Evènements
Faisons une petite pause, et décrivons les définitions de commandes de gestion d’événement sur l’esclave. Voici un exemple…
define command {
command_name handle-master-host-event
command_line /usr/local/nagios/libexec/eventhandlers/handle-master-host-event $HOSTSTATE$ $HOSTSTATETYPE$
}
define command {
command_name handle-master-proc-event
command_line /usr/local/nagios/libexec/eventhandlers/handle-master-proc-event $SERVICESTATE$ $SERVICESTATETYPE$
}
Cela implique que vous ayez placé les scripts de gestion d’événements dans le répertoire /usr/local/nagios/libexec/eventhandlers. Vous pouvez les placer ailleurs, mais vous devrez modifier les exemples que j’ai donnés ici.
Scripts de Gestion d’Evènements
Ok, regardons à quoi ressemble ce script…
Gestionnaire d’Evènement de système (handle-master-host-event):
#!/bin/sh
# Only take action on hard host states…
case "$2" in
HARD)
case "$1" in
DOWN)
# The master host has gone down!
# We should now become the master host and take
# over the responsibilities of monitoring the
# network, so enable notifications…
/usr/local/nagios/libexec/eventhandlers/enable_notifications
;;
UP)
# The master host has recovered!
# We should go back to being the slave host and
# let the master host do the monitoring, so
# disable notifications…
/usr/local/nagios/libexec/eventhandlers/disable_notifications
;;
esac
;;
esac
exit 0
Gestionnaire d’Evènements de Service (handle-master-proc-event):
#!/bin/sh
# Only take action on hard service states…
case "$2" in
HARD)
case "$1" in
CRITICAL)
# The master Nagios process is not running!
# We should now become the master host and
# take over the responsibility of monitoring
# the network, so enable notifications…
/usr/local/nagios/libexec/eventhandlers/enable_notifications
;;
WARNING)
UNKNOWN)
# The master Nagios process may or may not
# be running.. We won't do anything here, but
# to be on the safe side you may decide you
# want the slave host to become the master in
# these situations…
;;
OK)
# The master Nagios process running again!
# We should go back to being the slave host,
# so disable notifications…
/usr/local/nagios/libexec/eventhandlers/disable_notifications
;;
esac
;;
esac
exit 0
Que fait ce script pour nous ?
La notification sur le système esclave (système E) est désactivée, donc il n’enverra pas de notifications pour les systèmes autant que pour les services tant que le processus Nagios fonctionne sur le système maître (système A).
Le processus Nagios sur le système esclave (système E) devient maître quand…
-
Le système maître (système A) tombe et le gestionnaire d’événement de système
handle-master-host-eventest exécuté. -
Le processus Nagios sur le système maître (système A) s’arrête de fonctionner et le gestionnaire d’événement du service
handle-master-proc-eventest exécuté.
Dès que le processus Nagios sur le système esclave (système E) a la notification activée, il sera capable d’envoyer des notifications quant aux services ou problèmes système ou encore les retours à la normale. A ce moment, le système E a effectivement pris la responsabilité de notifier les contacts des problèmes de systèmes et services!
Le processus Nagios sur le système E retourne à son état d’esclave quand…
-
Le système A revient à la normale et le gestionnaire d’événement de système
handle-master-host-eventest exécuté. -
Le processus Nagios sur le système A revient à la normale et que le gestionnaire d’événement de service
handle-master-proc-eventest exécuté.
Dès que le processus Nagios sur le système E est désactivé, il n’enverra plus de notification concernant les problèmes liés aux services et aux systèmes ou encore les retours à la normale. Dès ce moment, le système E a pris la responsabilité de notifier les contacts des problèmes du processus Nagios sur le système A. Tout revient maintenant dans le même état que lorsque l’on a démarré!
Délais
La redondance dans Nagios n’est en rien parfaite. Un des nombreux problèmes est le délai entre le moment où le maître tombe et que l’esclave prend le relais. En voici les raisons…
-
L’intervalle entre la rupture du système maître et la première fois que le système esclave détecte le problème.
-
Le temps qu’il faut pour vérifier que le système maître a réellement un problème (en utilisant une nouvelle fois la commande ’check’ d’un service ou d’un système sur le système esclave)
-
Le temps entre l’exécution du gestionnaire d’événement et la fois suivante où Nagios va vérifier la présence d’une commande externe
Vous pouvez minimiser ce délai en…
-
S’assurant que le processus Nagios sur le système E (re)vérifie un ou plusieurs services avec une fréquence élevée. Ceci peut être fait en utilisant les arguments
check_intervaletretry_intervaldans chaque définition de service. -
S’assurer que le nombre de re-vérifications de la présence du système A (sur le système E) permette une détection des problèmes liés au système plus rapidement. Ceci peut être fait en utilisant l’argument
max_check_attemptsdans la définition du système. -
Augmenter la fréquence de vérification des commandes externes sur le système E. Ceci peut être fait en modifiant l’option
command_check_intervaldans le fichier de configuration principal.
Quand Nagios revient à la normale sur le système A, il y a aussi un délai avant que le système E ne redevienne esclave. C’est du aux faits suivants…
-
Le temps entre le retour à la normale du système A la fois suivante où le processus Nagios sur le système E détecte le retour à la normale.
-
L’intervalle entre l’exécution du gestionnaire d’événement sur le système E et la fois suivante où le processus Nagios sur le système E vérifie la présence de commandes externes
Les intervalles exacts entre le transfert des responsabilités de supervision dépendent du nombre de services définis, l’intervalle auquel les services sont vérifiés, et un peu de chance. A tous niveaux, c’est mieux que rien.
Cas spéciaux
Il y a une chose à laquelle il faut être attentif… Si le système A tombe, le système de notifications sur le système E sera activé et prendra la responsabilité de notifier les contacts de problèmes. Lorsque le système A revient à la normale, le système E aura sa notification désactivée. Si, quand le système A revient à la normale, le processus Nagios ne redémarre pas correctement, il y aura une période de temps où aucun système ne notifiera les contacts de problèmes! Heureusement on peut compter sur la logique de vérification de services de Nagios. La fois suivante où le processus Nagios sur le système E vérifie l’état du processus Nagios sur le système A, il verra qu’il ne fonctionne pas. Le système E aura donc sa notification activée et prendra la responsabilité de notifier les contacts des problèmes.
Le temps où aucun système ne surveille est assez difficile à déterminer. Toutefois, cette période peut être minimisée en augmentant la fréquence de vérification (sur le système E) du processus Nagios sur le système A. Le reste est une question de chance, mais le temps de blackout total ne devrait pas être trop mauvais.
Introduction
La supervision avec gestion de panne est pratiquement identique. Il existe quand même des différences avec le système précédent scénario 1).
Buts
Le but principal de la gestion de panne est d’avoir le processus Nagios sur le système esclave en hibernation tant que le processus Nagios sur le système maitre fonctionne. Si le processus sur le système maître arrête de fonctionner (ou si le système tombe), le processus Nagios sur le système esclave commence à tout surveiller.
Bien que la méthode décrite dans la partie scénario 1 permette de continuer à recevoir la notification si le système maitre tombe, il y a quelques pièges. Le plus gros problème est que le système esclave surveille les mêmes systèmes que le maitre au même moment! Ceci peut causer des problèmes de trafic excessif et charger les machines surveillées si vous avez beaucoup de services définis. Voici une manière de contourner ce problème…
Réglages initiaux du programme
Désactiver la vérification active des services et la notification sur le système esclave en utilisant les paramètres execute_service_checks et enable_notifications . Ceci évitera au système esclave de surveiller les services et les systèmes et d’envoyer des notifications tant que le processus Nagios sur le système maître fonctionne. Assurez-vous d’avoir le paramètre check_external_commands activée sur le système esclave.
Vérification du processus principal
Créer un tâche programmée [cron job] sur le système esclave qui lance périodiquement un script (disons toutes les minutes) qui vérifie l’état du processus Nagios sur le système maître (en utilisant le plugin check_nrpe sur le système esclave et le démon NRPE sur le système maître). Le script va vérifier le code de retour du plugin check_nrpe. S’il retourne un état non-OK, le script va envoyer les commandes appropriées au fichier de commandes externes pour activer la notification et la surveillance des services. Si le plugin retourne un état OK, le script enverra les commandes pour désactiver la surveillance active des services et la notification.
En procédant comme suit, vous n’utilisez qu’un processus de surveillance de système et de service à la fois, ce qui est plus efficace que de surveiller en double.
Notez aussi que vous ne devez pas définir de gestionnaires d’événements comme défini dans le scénario 1, car les contraintes sont surmontées de manière différente.
Cas Supplémentaires
Vous avez maintenant implémenté une gestion de panne de manière plutôt basique. Il y a toutefois d’autres manières de procéder pour que cela fonctionne de manière plus douce.
Le gros problème avec cette technique est surtout le fait que l’esclave ne connait pas l’état courant des services ou des systèmes au moment même où il prend à sa charge le travail de surveillance. Une manière de solutionner ce problème est d’activer la commande ocsp sur le système maître et de lui demander de rapporter les résultats des vérifications à l’esclave en utilisant l’addon NSCA De cette manière, le système esclave possède un statut mis à jour des informations de tous les services et des systèmes s’il venait à prendre en charge la surveillance. Tant que les vérifications actives ne sont pas activées sur le système esclave, il n’effectuera aucune vérification active. Malgré tout, il exécutera les vérifications si nécessaire. Cela signifie qu’autant le maître que l’esclave exécuteront les vérifications de système comme il le faut, ce qui n’est pas vraiment une bonne affaire puisque la majorité des surveillances fonctionnent par rapport aux services.