Chapitre 69. Intégration d'un TCP Wrapper
Table des matières
Introduction
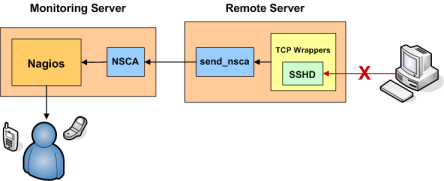
Cet exemple explique comment générer aisément des alertes dans Nagios pour des connexions rejetées par un TCP wrapper (encapsuleur TCP). Ces explications supposent que l'hôte pour lequel vous générez ces alertes (i.e. l'hôte sur lequel vous utilisez le TCP wrappers) n'est pas le même hôte que celui sur lequel Nagios est installé. Si vous souhaitez générer des alertes sur l'hôte Nagios, vous aurez besoin de faire quelques modifications à l'exemple que je vous propose. Je suppose également que vous avez installé le démon nsca sur la machine de surpervision et le client NSCA (send_nsca) sur la machine qui génère les alertes TCP wrappers.
Il y a quelques pré-requis à savoir :
-
Vous êtes maintenant familiariser avec Chapitre 31, Les contrôles passifs et comment les utiliser.
-
Vous êtes maintenant familiariser avec Volatile Services et comment les utiliser.
-
L'hôte avec lequel vous allez générer des alertes est une machine distance que l'on appellera firestorm. Si vous voulez générer les alertes TCP Wrapper sur le même hôte que votre serveur de supervision, il faudra adapter à vos besoins les exemples ci-dessous.
-
Vous avez installé NSCA sur votre serveur de supervision et le client NSCA (send_nsca) sur la machine distance qui enverra des alertes TCP Wrapper.
Définition du Service
Si vous ne l'avez pas encore fait, créez une définition d'hôte pour l'hôte à superviser (firestorm).
Tout d'abord vous devez définir un service dans votre fichier de configuration des objets pour les alertes du TCP wrapper. En supposant que l'hôte émettant les alertes s'appelle firestorm, un exemple de définition pourrait ressembler à quelque chose comme ça :
define service {
host_name firestorm
service_description TCP Wrappers
is_volatile 1
active_checks_enabled 0
passive_checks_enabled 1
max_check_attempts 1
check_command check_none
...
}
Il est important de noter que
-
le service à l'option volatile activée. Cette option est activée parce que nous voulons qu'une notification soit générée pour toutes les alertes survenant.
-
Notez également que les contrôles actifs sont désactivés pour ce service, alors que les contrôles passifs sont activés
-
Le
max_check_attemptsà 1 signifie que ce service enverra des alertes dès son premier changement d'état.
Configuration du TCP Wrapper
Maintenant, il faut modifier le fichier /etc/hosts.deny sur la machine firestorm. Pour que l'encapsuleur TCP envoie une alerte à chaque connexion refusée, vous devez ajouter une ligne de ce type:
ALL: ALL: RFC931: twist (/usr/local/nagios/libexec/eventhandlers/handle_tcp_wrapper %h %d)&
Cette ligne suppose qu'il existe un script appellé handle_tcp_wrapper dans le répertoire /usr/local/nagios/libexec/eventhandlers/ sur firestorm. Le répertoire et le nom du script peuvent être changés comme vous le voulez.
Écriture du script
La dernière chose à faire est d'écrire le script handle_tcp_wrapper sur firestorm qui enverra les alertes à l'hôte de supervision. Cela donnera quelque chose qui ressemblera à ça :
#!/bin/sh
/usr/local/nagios/libexec/eventhandlers/submit_check_result firestorm "TCP Wrappers" 2 "Denied $2-$1" > /dev/null 2> /dev/null
Notez que le script handle_tcp_wrapper appelle le script submit_check_result pour envoyer des alertes à l'hôte chargé de supervision. Supposons que votre hôte de supervision s'appelle monitor, le script submit check_result pourrait ressembler à ceci (vous devrez éventuellement modifier le script pour spécifier l'emplacement du programme send_nsca sur firestorm):
#!/bin/sh
# Arguments
# $1 = name of host in service definition
# $2 = name/description of service in service definition
# $3 = return code
# $4 = outputs
/bin/echo -e "$1\t$2\t$3\t$4\n" | /usr/local/nagios/bin/send_nsca monitor -c /usr/local/nagios/etc/send_nsca.cfg
Finition
Maintenant que vous avez configuré tout ce dont vous avez besoin, vous devez redémarrer le processus inetd sur firestorm et redémarrer Nagios sur votre serveur de supervision. C'est tout ! Quand le TCP wrapper sur firestorm refusera une connexion, vous devriez recevoir des alertes via Nagios. Cela ressemblera à ça : Denied sshd2-sdn-ar-002mnminnP321.dialsprint.net