Chapitre 14. Supervision des routeurs et des switchs.
Table des matières
Ce document décrit la façon dont vous pouvez superviser des routeurs et switchs réseaux. Quelques switchs et hubs bon marché non manageables n'ont pas d'adresse IP et sont invisibles sur votre réseau, il n'y a donc aucun moyen de les superviser. Les routeurs et switchs plus chers ont une adresse assignée et peuvent donc être supervisés en les pingant ou en utilisant SNMP pour interroger les informations de statut.
Introduction
Je vais décrire la façon dont vous pouvez superviser les choses suivantes sur vos switchs, hubs et routeurs:
Ces instructions impliquent que vous ayez installé Nagios comme précisé dans le guide rapide. Les exemples de configuration ci-dessous font référence aux objets de configuration définis dans les fichiers d'exemples (commands.cfg, templates.cfg, etc.) qui ont été installé si vous avez suivi le guide rapide.
Vue globale
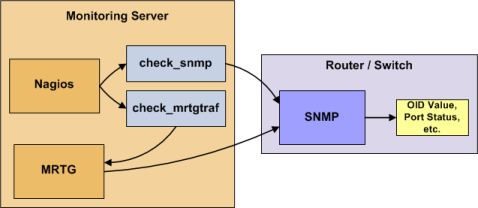
La supervision des switchs et routeurs peut au choix être simple ou plus évoluée suivant le type d'équipements que vous souhaitez superviser. Dans le cas où ce sont des composants critiques de votre infrastrcuture, vous voudrez sans aucun doute les superviser d'une façon au moins basique.
Les switchs et les routeurs peuvent facilement être supervisés en les pingant pour déterminer le nombre de paquets perdus, RTA, etc. Si votre switch supporte SNMP, vous pouvez superviser l'état des ports, etc. avec le plugin check_snmp et la bande passante avec check_mrtgtraf plugin (si vous utilisez MRTG).
Le plugin check_snmp sera compilé et installé seulement si vous avez les paquets net-snmp et net-snmp-utils installés sur votre système. Assurez-vous que le plugin soit présent dans /usr/local/nagios/libexec avant de continuer. Si ce n'est pas le cas, installez net-snmp, net-snmp-utils et recompilez/réinstallez les plugins Nagios.
Étapes
Il y a plusieurs étapes à suivre pour pouvoir superviser un nouveau routeur ou switch. Les voici:
-
Procédez aux pré-requis nécessaires la première fois
-
Créez de nouvelles définitions d'hôte et service pour la supervision du périphérique.
-
Redémarrez le démon Nagios
Ce qui est déjà fait pour vous
Pour vous rendre la vie un peu plus facile, quelques tâches de configuration ont déjà été faites pour vous :
-
Deux définitions de commandes (check_snmp et check_local_mrtgtraf) ont été ajoutées au fichier
commands.cfg. Elles vous permettent d'utiliser les plugins check_snmp et check_mrtgtraf pour superviser les routeurs réseaux. -
Un gabarit d'hôte de type switch (nommé generic-switch) a déjà été créé dans le fichier
templates.cfg. Cela vous permet de rajouter des définitions d'hôtes de type routeur/switch de façon simple.
Les fichiers de configuration mentionnés ci-dessus peuvent être trouvés dans le répertoire /usr/local/nagios/etc/objects/. Vous pouvez modifier les définitions de ceux-ci ou en créer de nouvelles pour répondre le mieux à votre besoin. Quoi qu'il en soit, je vous recommande d'attendre d'avoir une meilleure connaissance de la configuration de Nagios avant de le faire. Pour le moment, contentez-vous de suivre les directions précisées ci-dessous et vous pourrez superviser vos routeurs/switchs réseaux en un rien de temps.
Pré-requis
La première fois que vous configurez Nagios pour superviser un switch réseau, vous avez un peu plus de travail à faire. Souvenez-vous, vous n'avez à le faire que pour le *premier* switch à superviser.
Éditez le fichier de configuration principal de Nagios.
#vi /usr/local/nagios/etc/nagios.cfg
Supprimez le caractère (#) du début de la ligne suivante du fichier de configuration principal :
#cfg_file=/usr/local/nagios/etc/objects/switch.cfg
Enregistrez le fichier et quittez.
Qu'avez-vous fait? Vous avez dit à Nagios de regarder dans le fichier /usr/local/nagios/etc/objects/switch.cfg pour y trouver des définitions d'objets additionnels. C'est là que vous ajouterez des définitions pour les routeurs et les switchs. Ce fichier de configuration contient déjà un exemple de definitions d'hôte et de service. Pour le *premier* routeur/switch que vous supervisez, vous pouvez simplement modifier les définitions d'exemple d'hôte et de service dans ce fichier plutôt que d'en créer de nouvelles.
Configuration de Nagios
Vous allez devoir créer quelques définitions d'objets pour pouvoir superviser un nouveau routeur/switch.
Éditez le fichier switch.cfg.
#vi /usr/local/nagios/etc/objects/switch.cfg
Ajouter une nouvelle définition d'hôte pour le switch que vous souhaitez superviser. Si c'est le *premier* que vous supervisez, vous pouvez simplement modifier l'exemple de définition d'hôte dans switch.cfg. Remplacez les champs host_name, alias, et address par les valeurs appropriées pour votre switch.
define host {
use generic-switch ; Inherit default values from a template
host_name linksys-srw224p ; The name we're giving to this switch
alias Linksys SRW224P Switch ; A longer name associated with the switch
address 192.168.1.253 ; IP address of the switch
hostgroups allhosts,switches ; Host groups this switch is associated with
}
Supervision des services
Vous pouvez ajouter maintenant quelques définitions de services (dans le même fichier de configuration) pour superviser différents aspects de votre switch. Si c'est le *premier* switch que vous supervisez, vous pouvez simplement modifier l'exemple de définition d'hôte dans switch.cfg.
Remplacez linksys-srw224p dans les exemples de définitions ci-dessous par le nom que vous avez renseigné dans le paramètre host_name que vous venez d'ajouter dans la définition d'hôte.
Supervision des paquets perdus et de la RTA
Ajoutez cette définition de service pour pouvoir superviser les paquets perdus et le temps moyen de réponse entre le serveur Nagios et le switch toutes les 5 minutes en conditions normales.
define service {
use generic-service
host_name linksys-srw224p
service_description PING
check_command check_ping!200.0,20%!600.0,60%
normal_check_interval 5
retry_check_interval 1
}
|
|
Hérite des valeurs définies dans le gabarit |
|
|
Le nom de l'hôte et du service associé |
|
|
La description du service |
|
|
La commande à utiliser pour superviser le service |
|
|
Contrôle le service toutes les 5 minutes en conditions normales |
|
|
Recontrôle le service toutes les minutes jusqu'à ce que son état final/hard soit déterminé |






Le service sera:
-
CRITICAL si le temps de réponse moyen (RTA) est plus élevé que 600 millisecondes ou que le nombre de paquets perdus est égal ou supérieur à 60%
-
WARNING si le RTA est supérieur à 200 ms ou que le nombre de paquets perdus est égal ou supérieur à 20%
-
OK si le RTA est inférieur à 200 ms et que le nombre de paquets perdus est inférieur à 20%
Supervision de l'information d'état SNMP
Si votre switch ou routeur supporte SNMP, vous pouvez superviser un tas d'information en utilisant le plugin check_snmp. Sinon, sautez cette section.
Ajoutez la définition de service suivante pour superviser le temps écoulé depuis la mise sous tension de votre switch.
define service {
use generic-service ; Inherit values from a template
host_name linksys-srw224p
service_description Uptime
check_command check_snmp!-C public -o sysUpTime.0
}
Dans le paramètre check_command de la définition de service ci-dessus, le -C public indique au plugin que le nom de communauté SNMP à utiliser est public et que -o sysUpTime.0 indique que l' OID doit être contrôlé.
Si vous souhaitez vous assurer qu'un port/interface particulier du switch est dans un état up, vous pouvez ajouter une définition de service comme celle-ci:
define service {
use generic-service ; Inherit values from a template
host_name linksys-srw224p
service_description Port 1 Link Status
check_command check_snmp!-C public -o ifOperStatus.1 -r 1 -m RFC1213-MIB
}
Dans l'exemple ci-dessus, -o ifOperStatus.1 fait référence à OID pour l'état opérationnel du port 1 sur le switch.
L'option -r 1 indique au plugin check_snmp de retourner un état OK si 1 est trouvé dans la réponse SNMP (1 indique que le port est up) et CRITICAL sinon.
L'option -m RFC1213-MIB est optionnel et indique la MIB à utiliser parmi celles installées sur votre système et peut aider à accélérer les choses.
Voilà pour l'exemple de supervision avec SNMP. Il y a des millions de choses qui peuvent être supervisées par SNMP, aussi est-ce à vous décider ce que dont vous avez besoin et ce que vous souhaitez superviser. Bonne chance!
Vous pouvez trouver les OIDs qui peuvent supervisés sur un switch en exécutant la commande suivante (remplacez 192.168.1.253 par l'adresse IP de votre switch): snmpwalk -v1 -c public 192.168.1.253 -m ALL .1
Supervision de la bande passante/trafic
Si vous supervisez l'usage de la bande passante de vos switchs et routeurs en utilisant MRTG , vous pouvez utiliser Nagios pour alerter quand les valeurs dépassent un seuil que vous spécifiez. Le plugin check_mrtgtraf (inclus dans la distribution de splugins Nagios) vous permet de le faire.
Vous aurez besoin que le plugin check_mrtgtraf connaisse l'emplacement du fichier où MRTG stocke ses données, ainsi que les seuils, etc. Dans mon exemple, je supervise un des ports d'un switch Linksys. Le fichier de log de MRTG est stocké dans /var/lib/mrtg/192.168.1.253_1.log. Voici la définition de service que j'utilise pour superviser les données de bande passante stockées dans ce fichier…
define service {
use generic-service ; Inherit values from a template
host_name linksys-srw224p
service_description Port 1 Bandwidth Usage
check_command check_local_mrtgtraf!/var/lib/mrtg/192.168.1.253_1.log!AVG!1000000,2000000!5000000,5000000!10
}
Dans l'exemple ci-dessus, l'option /var/lib/mrtg/192.168.1.253_1.log passée à la commande check_local_mrtgtraf indique au plugin dans quel fichier de log MRTG il doit aller lire.
L'option AVG indique qu'il doit utiliser des statistiques basées sur la moyene de la bande passante. Les arguments 1000000,2000000 sont les seuils de warning (en bytes) pour le taux de trafic entrant.
Les arguments 5000000,5000000 sont des seuils critiques (en bytes) pour le taux de trafic sortant. L' 10 option indique au plugin de renvoyer un état CRITICAL si le fichier de log MRTG est plus vieux que 10 minutes (il devrait être mis à jour toutes les 5 minutes).
Enregistrez le fichier.
Redémarrage de Nagios
Une fois que vous avez ajouté les nouvelles définitions d'hôte et de service dans le fichier switch.cfg, vous êtes prêt à démarrer la supervision d'un routeur/switch. Pour cela, vous aurez besoin de vérifier votre configuration et redémarrez Nagios.
Si le processus de vérification produit n'importe quel message d'erreur, réglez d'abord vos problèmes de configuration avant de continuer. Assurez-vous de ne pas redémarrer Nagios avant que le processus de vérification ne se déroule sans erreur!